
Let’s first quickly explain what sentiment analysis actually is. Sentiment analysis is a programmatic way of determining the mood of a specific text and therefore falls in the broader category of NLP (Natural Language Processing).
With sentiment analysis, you are able to predict whether a given text has a positive or negative meaning.
A good example for that would be predicting whether a review of a product is a positive review or a negative review. Such as the ones we will use in this tutorial.
In this tutorial we will use a dataset provided by yelp! which consists of reviews for different locations like restaurants, tattoo-shops and so on…
The goal of this tutorial is to prepare the data, train a machine learning model and predict whether a review that has not been seen by the model is a negative or positive review.
Data Preparation
The data is formatted as json-objects where each line in the file corresponds to one review and each review is a json-object.
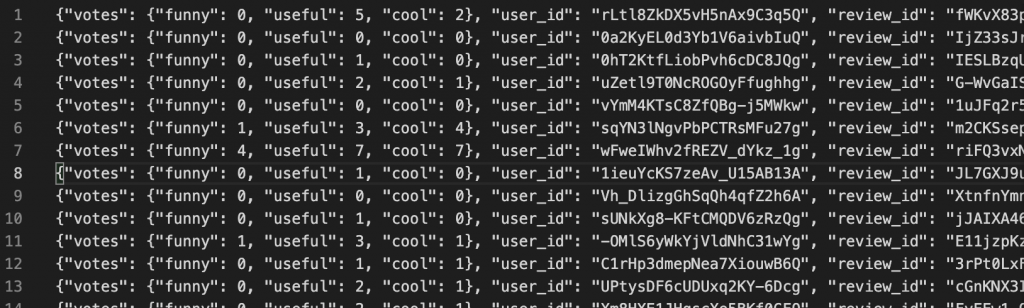
To further inspect the data I grabbed one entry and reformatted it.
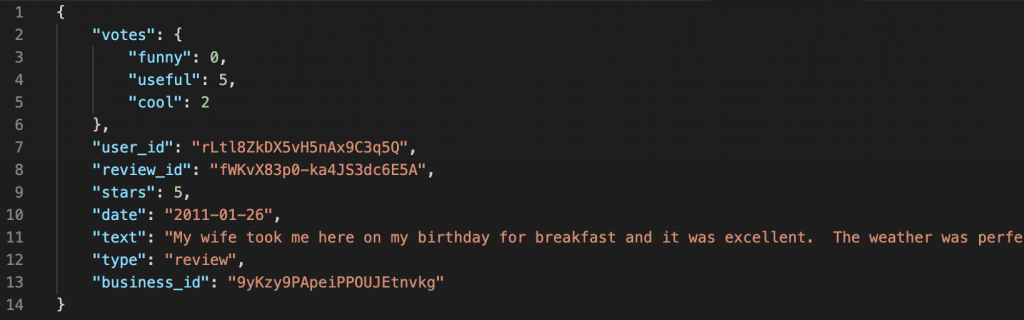
The for this tutorial relevant parts of the objects are the “stars” and “text” attributes.
Even tho the file is called json it does not contain valid json. It is just a file with many lines where each line is a json-object.
So the next step would be to make the file a valid json-document.
|
1 2 3 4 5 6 |
json_data = None with open('../data/yelp_academic_dataset_review.json') as data_file: lines = data_file.readlines() joined_lines = "[" + ",".join(lines) + "]" json_data = j.loads(joined_lines) |
- This code reads the data file in a list where each line is a separate list entry.
- Joins the list to string using “,” as the joining character
- wraps the new string with “[” and “]”
Turning the contents of the file into a huge json-array
With the initial transformation in place we are now able to load the data into a pandas dataframe and have a look at it
|
1 2 |
data = pd.DataFrame(json_data) data.head() |
Since we want to predict whether a review is a positive or negative review we need some sort of measure for the mood of a review. The measure that we will be using is the stars-rating. We assume that star-ratings of 1 or 2 are negative, star-ratings of 4 or 5 are positive and star-ratings of 3 are not clearly assignable and are therefor ignored.
So let’s prepare the data reflect this logic.
|
1 2 3 |
data = data[data.stars != 3] data['sentiment'] = data['stars'] >= 4 data.head() |
- first we drop all 3-star ratings
- then we create a new column in the dataframe called “sentiment”, where the values are 1 (True) for positive reviews and 0 (False) for negative reviews
With this we have now finished the data preparation and will start building our machine learning model. Yeay!
Model Training
Here is the code for our machine learning model let’s inspect it.
|
1 2 3 4 5 6 7 8 9 10 11 |
X_train, X_test, y_train, y_test = train_test_split(data, data.sentiment, test_size=0.2) # - count = CountVectorizer() temp = count.fit_transform(X_train.text) tdif = TfidfTransformer() temp2 = tdif.fit_transform(temp) text_regression = LogisticRegression() model = text_regression.fit(temp2, y_train) |
- We create our training and test splits using the reviews. As you see we use the sentiment column that we created based on the star ratings as our target. We use 20% of the data as test data and 80% as training data.
- The next step is to use a CountVectorizer. This will create a bag-of-words with word counts so that the algorithm can learn that if the word “great” occurs 3 times it is probably a good review
- After the CountVectorizer we use the TfidfTransformer. Tf-Idf stands for term frequency, inverse document frequency. The goal is here to model the relevancy of words. The idea is that if a word is frequent in the current document and not so frequent in all documents then it has high relevancy. Words that appear in many documents like “and”, “the” and so on will have relatively low relevancy.
- Next, we need to choose a classification algorithm since sentiment analysis as we perform it in this tutorial is a classification problem. We will use the quite simple LogisticRegression algorithm and fit it on our training data.
Now we have a trained machine learning model. Let’s use it.
Predicting / Evaluation
The first thing that you should usually do after successfully training your machine learning model is to evaluate it based on the standard measures for the type of machine learning problem you are solving. For classification that would be for example F1-score, Precision, Recall or Accuracy.
I have a separate blog post about evaluating classification models… so check that out for a deeper dive into that topic.
For sake of simplicity let’s check the accuracy of our newly created machine learning model.
|
1 2 3 |
prediction_data = tdif.transform(count.transform(X_test.text)) predicted = model.predict(prediction_data) print(np.mean(predicted == y_test)) |
And now would be the time to play around with the model and see how well it predicts reviews that you come up with.
You could predict the sentiment of your own review with this code:
|
1 |
print(model.predict(tdif.transform(count.transform(["this product was a great video game"])))) |
Conclusion
I hope this short and quite basic introduction into machine learning and sentiment analysis was useful for you and gave you a first glance into how to apply machine learning to real world tasks.
The current state of the art models are much more complex than this one… but everybody needs some easy way to start and I hope you will continue your journey in the world of data science.
You can find the complete code and data for this tutorial at: https://github.com/coding-maniacs/sentiment_tut1


